
Ma doctrine d'artisan développeur
Journaux liées à cette note :
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
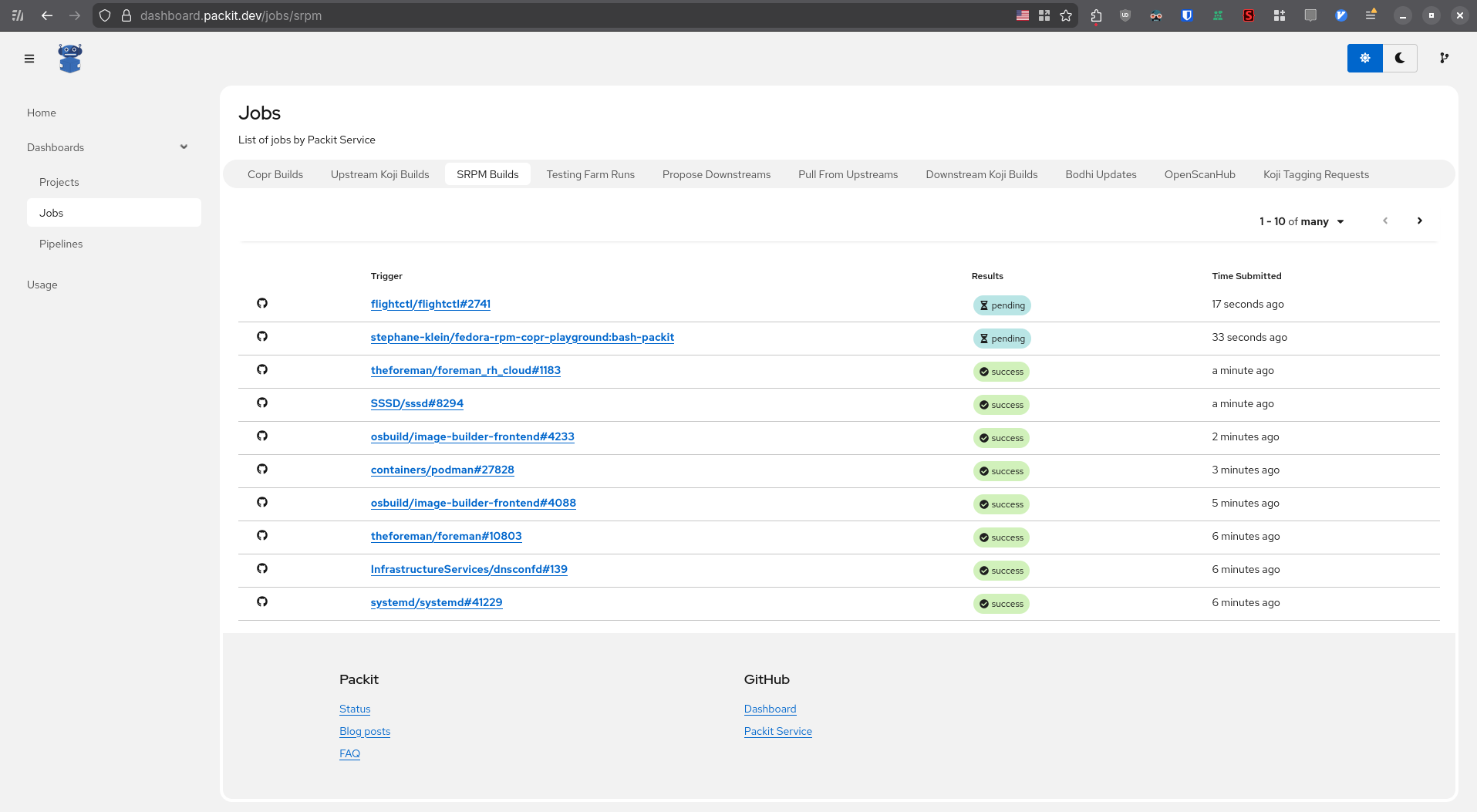
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
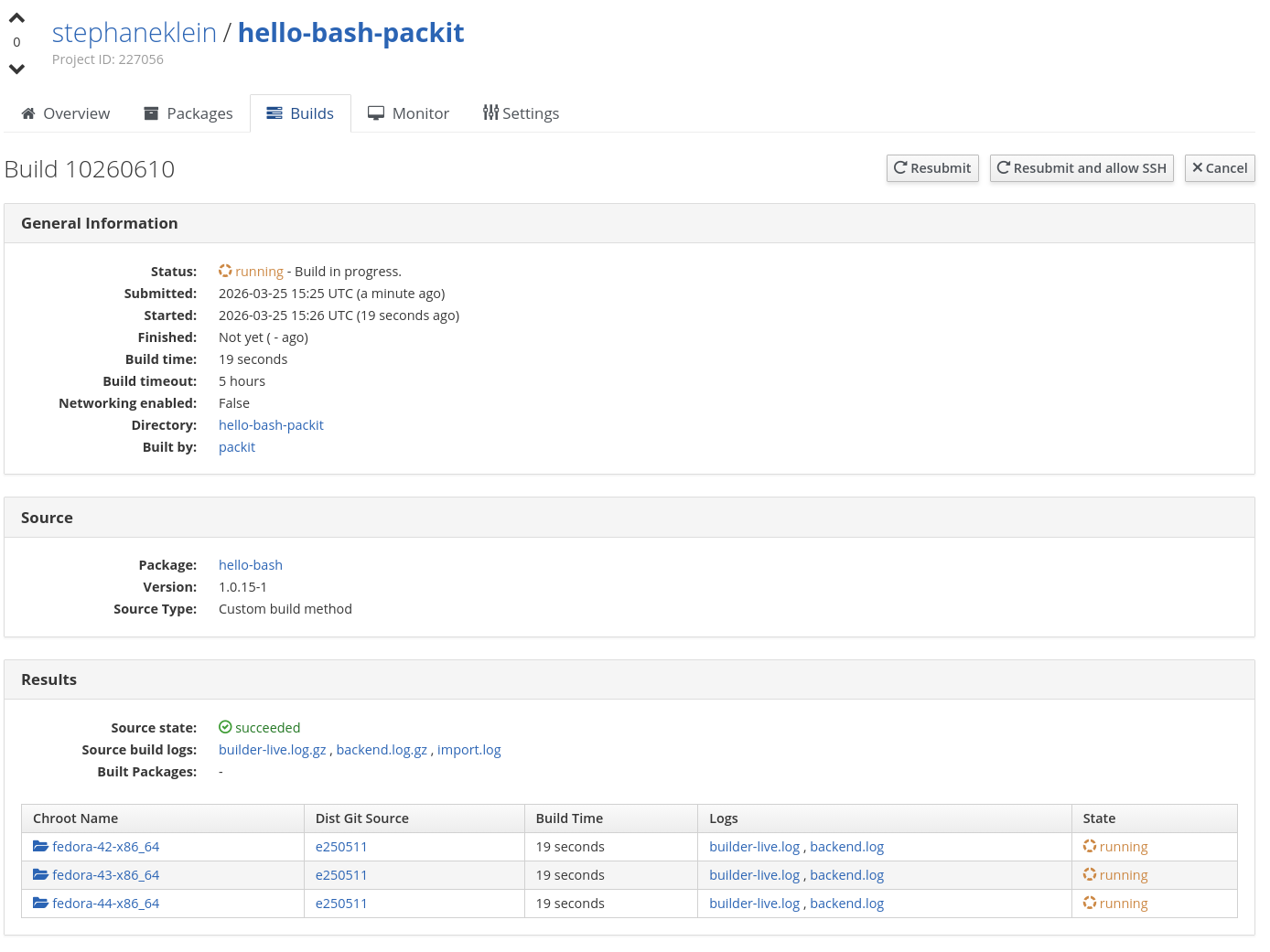
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
J'ai découvert class-variance-authority et tailwinds-variants
Jusqu'à présent, pour la gestion conditionnelle des classes CSS dans mes projets ReactJS ou Svelte, j'utilisais clsx.
Pour Svelte en particulier, j'utilise souvent directement le mécanisme conditionnel natif de l'attribut "class" du framework.
Aujourd'hui, dans un projet professionnel ReactJS, #JaiDécouvert la librairie conditionnelle class-variance-authority.
Cette librairie existe depuis debut 2022 et voici un exemple d'utilisation de class-variance-authority :
<script>
import { cva } from 'class-variance-authority';
const button = cva(
'font-semibold rounded', // équivalent au paramètre `base:` utlisé par tailwind-variants
{
variants: {
intent: {
primary: 'bg-blue-500 text-white hover:bg-blue-600',
secondary: 'bg-gray-200 text-gray-900 hover:bg-gray-300'
},
size: {
sm: 'px-3 py-1 text-sm',
md: 'px-4 py-2 text-base',
lg: 'px-6 py-3 text-lg'
}
},
compoundVariants: [
{
intent: 'primary',
size: 'lg',
class: 'uppercase tracking-wide' // <= appliqué seulement si intent="primary" et size="lg"
}
],
defaultVariants: {
intent: 'primary',
size: 'md'
}
}
);
export let intent = 'primary';
export let size = 'md';
</script>
<button class={button({ intent, size })}>
<slot />
</button>
Je trouve cette approche plus élégante que clsx pour des besoins complexes, comme la création d'un design system.
Dans la même famille de librairie, il existe aussi tailwind-merge que j'avais déjà identifié mais sans avoir jamais pris le temps d'étudier. Ses fonctionnalités sont très simples et minimalistes :
Merge Tailwind CSS classes without style conflicts
Claude Sonnet 4.5 m'a fait découvrir tailwind-variants, une alternative à class-variance-authority. Cette lib est spécifique à Tailwind CSS mais offre de meilleures performances et des fonctionnalités supplémentaires par rapport à class-variance-authority.
Le projet a été créé début 2023, soit environ 1 an après class-variance-authority.
Voici un tableau comparant les fonctionnalités de tailwind-variants et class-variance-authority :
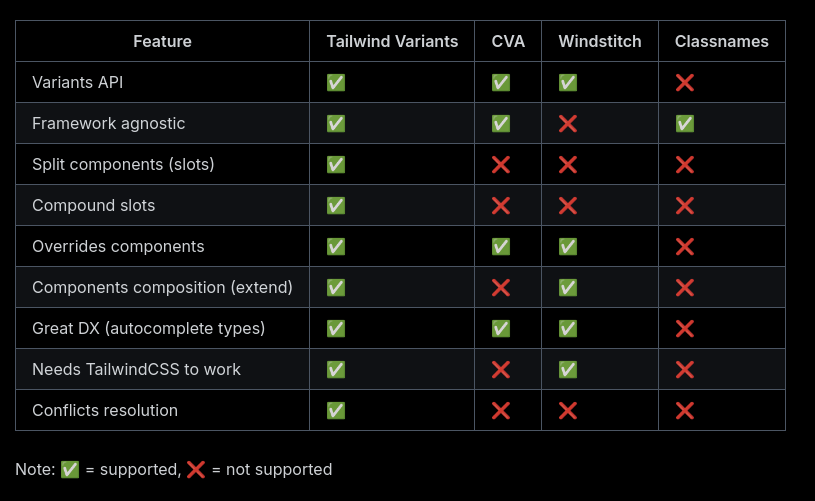
La dernière section de la page Tailwind Variants - Comparison explique l'historique de la lib avec class-variance-authority et les raisons qui ont motivé sa création.
Après quelques difficultés, je pense avoir saisi l'intérêt de la fonctionnalité "slots", disponible dans tailwind-variants mais absente de class-variance-authority.
Si un jour je dois créer des composants de design system avancés dans un projet ReactJS ou Svelte, je pense que j'utiliserai tailwind-variants.
De 2000 à 2016, j'ai essentiellement déployé la distribution Linux Debian sur mes serveurs et après cette date des Ubuntu LTS.
Depuis 2022, j'utilise une Fedora sur ma workstation. Distribution que je maitrise et que j'apprécie de plus en plus.
J'envisage peut-être d'utiliser une distribution de la famille Fedora sur mes serveurs personnels.
J'avais suivi de loin les événements autour de CentOS en décembre 2020 :
- 8 décembre 2020 : CentOS Project shifts focus to CentOS Stream
- 16 décembre 2020 : Rocky Linux: A CentOS replacement by the CentOS founder
J'ai enfin compris l'origine du nom Rocky Linux :
"Thinking back to early CentOS days... My cofounder was Rocky McGaugh. He is no longer with us, so as a H/T to him, who never got to see the success that CentOS came to be, I introduce to you...Rocky Linux"
J'aime beaucoup cet hommage 🤗 !
J'ai étudié AlmaLinux et il me semble que cette distribution est principalement développée par l'entreprise CloudLinux, une entreprise à but lucratif qui vend du support Linux.
Personnellement, je trouve le positionnement d'AlmaLinux peu "fair-play" envers Red Hat : Red Hat investit massivement dans le développement de Red Hat Enterprise Linux et AlmaLinux récupère ce travail gratuitement pour ensuite vendre du support commercial en concurrence directe.
À mon avis, si une entreprise souhaite un vrai support sur une distribution de la famille Red Hat, elle devrait se tourner vers Red Hat Enterprise Linux et acheter du support directement à Red Hat plutôt qu'à CloudLinux.
Suite à ce constat, j'ai décidé d'utiliser Rocky Linux plutôt qu'AlmaLinux.
21h30 : j'ai reçu le message suivant sur Mastodon :
@stephane_klein you have things quite backwards. AlmaLinux is a non-profit foundation while Rocky is owned 100% by Greg kurtzer and they have over $100M in venture capital funding.
AlmaLinux has a community-elected board.
Suite à ce message, j'ai essayé d'en savoir plus, mais il est difficile d'y voir clair.
Par exemple : I’m confused about the different organizational structure when it comes to Rocky and Alma.
La page "AlmaLinux OS Foundation " que j'ai consultée m'a particulièrement plu.
J'ai révisé ma position, j'ai décidé d'utiliser AlmaLinux plutôt que Rocky Linux.
2025-12-02 : j'ai révisé ma position, pour des serveurs de production, j'ai décidé d'utiliser la version stable de CoreOS, plutôt que AlmaLinux ou Rocky Linux.
bridge-utils est déprécié, je dois remplacer "brctl" par "ip link"
En étudiant IPv6 et Linux bridge, j'ai découvert que le projet bridge-utils est déprécié. À la place, il faut utiliser iproute2.
Ce qui signifie que je ne dois plus utiliser la commande brctl, chose que j'ignorais jusqu'à ce matin.
iproute2 remplace aussi le projet net-tools. Par exemple, les commandes suivantes sont aussi dépréciées :
ifconfigremplacé parip addretip linkrouteremplacé parip routearpremplacé parip neighbrctlremplacé parip linkiptunnelremplacé parip tunnelnameifremplacé parip link set nameipmaddrremplacé parip maddr
Au-delà des aspects techniques — iproute2 utilise Netlink plutôt que ioctl — l'expérience utilisateur me semble plus cohérente.
J'ai une préférence pour une commande unique ip accompagnée de sous-commandes plutôt que pour un ensemble de commandes disparates.
Cette logique de sous-commandes s'inscrit dans une tendance générale de l'écosystème Linux, et je pense que c'est une bonne direction.
Je pense notamment à systemctl, timedatectl, hostnamectl, localectl, loginctl, apt, etc.
Quand j'ai débuté sous Linux en 1999, j'ai été habitué à utiliser les commande ifup et ifdown qui sont en réalité des scripts bash qui appellent entre autre ifconfig.
Ces scripts ont été abandonnés par les distributions Linux qui sont passées à systemd et NetworkManager.
En simplifiant, l'équivalent des commandes suivantes avec NetworkManager :
$ ifconfig
$ ifup eth0
$ ifdown eth0
est :
$ nmcli device status
$ nmcli connection up <nom_de_connexion>
$ nmcli connection down <nom_de_connexion>
Contrairement à mon intuition initiale, NetworkManager n'est pas un simple "wrapper" de la commande ip d'iproute2.
En fait, nmcli fonctionne de manière totalement indépendante d'iproute2, il utilise l'interface Netlink comme l'illustre cet exemple de la commande nmcli device show :
nmcli device show
↓ (Method call via D-Bus)
org.freedesktop.NetworkManager.Device.GetProperties()
↓ (NetworkManager traite la requête)
nl_send_simple(sock, RTM_GETLINK, ...)
↓ (Socket netlink vers kernel)
Kernel: netlink_rcv() → rtnetlink_rcv()
↓ (Retour des données)
RTM_NEWLINK response
↓ (libnl parse la réponse)
NetworkManager met à jour ses structures
↓ (Réponse D-Bus)
nmcli formate et affiche les données
Autre différence, contrairement à iproute2, les changements effectués par NetworkManager sont automatiquement persistants et il peut réagir à des événements, tel que le branchement d'un câble réseau et la présence d'un réseau WiFi connu.
Les paramètres de configuration de NetworkManager se trouvent dans les fichiers suivants :
- Fichiers de configuration globale de NetworkManager :
# Fichier principal
/etc/NetworkManager/NetworkManager.conf
# Fichiers de configuration additionnels
/etc/NetworkManager/conf.d/*.conf
- Fichiers de configuration des connexions NetworkManager :
# Configurations système (root)
/etc/NetworkManager/system-connections/
# Configurations utilisateur
~/.config/NetworkManager/user-connections/
Comme souvent, Ubuntu propose un outil "maison", nommé netplan qui propose un autre format de configuration. Mais je préfère utiliser nmcli qui est plus complet et a l'avantage d'être la solution mainstream supportée par toutes les distributions Linux.
J'ai lu le très bon billet d'Athoune sur Kloset, moteur de stockage de backup de Plakar
Il y a un an, Alexandre m'avait fait découvrir Kopia : Je découvre Kopia, une alternative à Restic.
Ma conclusion était :
Ma doctrine pour le moment : je vais rester sur restic.
En septembre 2024, j'ai découvert rustic, un clone de restic recodé en Rust. Pour le moment, je n'ai aucun avis sur rustic.
Il y a quelques semaines, Athoune m'a fait découvrir Plakar, mais je n'avais pas encore pris le temps d'étudier ce que cet outil de backup apportait de plus que restic que j'ai l'habitude d'utiliser.
Depuis, Athoune a eu la bonne idée d'écrire un article très détaillé sur Plakar, enfin, surtout son moteur de stockage avant-gardiste nommé Kloset : "Kloset sur la table de dissection" (au minimum 30 minutes de lecture).
Ce que je retiens, c'est que Kloset propose un système de déduplication plus performant que par exemple celui de restic qui est basé sur Rabin Fingerprints :
For creating a backup, restic scans the source directory for all files, sub-directories and other entries. The data from each file is split into variable length Blobs cut at offsets defined by a sliding window of 64 bytes. The implementation uses Rabin Fingerprints for implementing this Content Defined Chunking (CDC). An irreducible polynomial is selected at random and saved in the file config when a repository is initialized, so that watermark attacks are much harder.
Files smaller than 512 KiB are not split, Blobs are of 512 KiB to 8 MiB in size. The implementation aims for 1 MiB Blob size on average.
For modified files, only modified Blobs have to be saved in a subsequent backup. This even works if bytes are inserted or removed at arbitrary positions within the file.
Au moment où j'écris ces lignes, je n'ai aucune idée des différences ou des points communs entre l'algorithme Rolling hash dont parle l'article et Rabin Fingerprints qu'utilise restic.
Chose suprernante, je trouve très peu de citations de Plakar ou kloset sur Hacker News ou Lobster :
- Recherche avec "Plakar"
- Hacker News
- dans les stories
- Mars 2021 : March 2021: backups with Plakar – poolp.org : 0 commentaire
- Octobre 2024 : Open source distributed, versioned backups with encryption and deduplication : 0 commentaires
- Mars 2025 : CDC Attack Mitigation in Plakar : 0 commentaires
- dans les commentaires
- dans les stories
- Lobsters => rien
- Hacker News
- Recherche avec "Kloset"
- Hacker News :
- Lobsters => rien
Je tiens à remercier Athoune pour l'écriture, qui m'a permis de découvrir de nombreuses choses 🤗.
J'ai découvert le support SSH agent de Bitwarden et ses conséquences sur l'utilisation de Age
J'ai utilisé le "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh" dans un projet professionnel et un collègue a rencontré un problème au niveau du script /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
Sa clé privée ssh n'était pas présente dans ~./ssh/ parce qu'il utilise "1Password SSH agent" (disponible depuis mars 2022).
Je ne connaissais pas cette fonctionnalité (merci).
#JaiDécouvert que cette fonctionnalité existe aussi dans Bitwarden depuis février 2025 : "SSH Agent".
#JaiDécouvert qu'une solution alternative pour Bitwarden existait depuis 2020 : bitwarden-ssh-agent. Mais beaucoup moins bien intégré à Bitwarden.
Au cours des 15 dernières années, j'ai régulièrement reçu des demandes de redéploiement de clés SSH de la part des développeurs, parfois plusieurs mois après leur onboarding. La cause principale : la plupart des développeurs ne pensent pas à sauvegarder leurs clés SSH dans leur gestionnaire de password et les perdent inévitablement lors du changement de workstation ou de réinstallation de leur système.
Face à ce constat récurrent, j'envisageais depuis plusieurs années de créer une issue chez Bitwarden pour leur proposer d'implémenter un système de sauvegarde automatique des clés SSH.
L'approche basée sur un ssh-agent ne m'avait jamais traversé l'esprit.
À l'avenir, j'envisage d'intégrer l'usage de Bitwarden SSH Agent (ou équivalent) dans les processus d'onboarding dont j'ai la responsabilité.
J'ai tenté d'ajouter le support de ssh-agent au script /scripts/decrypt_secrets.sh, mais d'après le thread "ssh-agent support", age ne semble pas supporter ssh-agent.
Conséquence : en attendant, j'ai demandé à mon collègue de placer sa clé privée ssh dans ~/.ssh/.
Bilan de poc-sveltekit-custom-server
Contexte et objectifs
Dans le projet gibbon-replay, j'ai besoin d'exécuter une tâche une fois par jour pour supprimer des anciennes sessions.
gibbon-replay utilise une base de données SQLite qui ne dispose pas nativement de fonctionnalité de type Time To Live, comme on peut trouver dans Clickhouse.
SQLite ne propose pas non plus d'équivalent à pg_cron — ce qui est tout à fait normal étant donnée que SQLite est une librairie et non pas un service à part entière.
Le projet gibbon-replay est un monolith (j'aime les monoliths !) et je souhaite conserver ce choix.
Face à ces contraintes, une solution consiste à intégrer une solution comme Cron for Node.js directement dans l'application gibbon-replay.
Je pense que je dois implémenter cela dans un SvelteKit Custom Server, ce qui me permettrait d'exécuter cette tâche de purge à intervalles réguliers tout en conservant l'architecture monolithique.
Il y a quelques jours, j'ai décidé de tester cette idée dans un POC nommé : poc-sveltekit-custom-server.
J'ai aussi décidé d'expérimenter un objectif supplémentaire dans ce POC : lancer la migration du modèle de données dès le lancement du monolith et non plus lors de la première requête HTTP reçue par le service.
Enfin, je souhaitais ne pas dégrader l'expérience développeur (DX), c'est à dire, je souhaitais pouvoir continuer à simplement utiliser :
$ pnpm run dev
ou
$ pnpm run build
$ pnpm run preview
sans différence avec un projet SvelteKit "vanilla".
Résultats du POC et enseignements
Tout d'abord, le POC fonctionne parfaitement 🙂, sans dégrader l'expérience développeur (DX), qui ressemble à ceci :
$ mise install
$ pnpm install
$ pnpm run load-seed-data
Start data model migration…
Data model migration completed
Start load seed data...
seed data loaded
Lancement du projet en mode développement :
$ pnpm run dev
Start data model migration…
Data model migration completed
Server started on http://localhost:5173 in development mode
Lancement du projet "buildé" :
$ pnpm run build
$ pnpm run preview
Start data model migration…
Data model migration completed
Server started on http://localhost:3000 in production mode
Les migrations et les données "seed.sql" se trouvent dans le dossier /sqls/.
Le SvelteKit Custom Server est implémenté dans le fichier src/server.js et il ressemble à ceci :
import express from 'express';
import cron from 'node-cron';
import db, { migrate } from '@lib/server/db.js';
const isDev = process.env.ENV !== 'production';
migrate(); // Lancement de la migration du modèle de donnée dès de lancement du serveur
// Configuration d'une tâche exécuté toutes les heures
cron.schedule(
'0 * * * *',
async () => {
console.log('Start task...');
console.log(db().query('SELECT * FROM posts'));
console.log('Task executed');
}
);
async function createServer() {
const app = express();
...
Personnellement, je trouve cela simple et minimaliste.
Point de difficulté
SvelteKit utilise des "module alias", comme par exemple $lib.
Problème, par défaut, ces "module alias" ne sont pas configurés lors de l'exécution de node src/server.js.
Pour me permettre d'importer dans src/server.js des modules de src/lib/server/* comme :
import db, { migrate } from '@lib/server/db.js';
j'ai utilisé la librairie esm-module-alias.
Ceci complexifie un peu le projet, j'ai dû configurer ceci dans /package.json :
{
"scripts": {
"dev": "ENV=development node --loader esm-module-alias/loader --no-warnings src/server.js",
"preview": "ENV=production node --loader esm-module-alias/loader --no-warnings build/server.js",
...
"aliases": {
"@lib": "src/lib/"
}
}
- ajout de
--loader esm-module-alias/loader --no-warnings - et la section
aliases
Et dans /vite.config.js :
export default defineConfig({
plugins: [sveltekit()],
resolve: {
alias: {
'@lib': path.resolve('./src/lib')
}
}
});
- ajout de
alias
Le fichier src/server.js contient du code spécifique en fonction de son contexte d'exécution ("dev" ou "buildé") :
if (isDev) {
const { createServer: createViteServer } = await import('vite');
const vite = await createViteServer({
server: { middlewareMode: true },
appType: 'custom'
});
app.use(vite.middlewares);
} else {
const { handler } = await import('./handler.js');
app.use(handler);
}
En mode "dev" il utilise Vite et en "buildé" il utilise le fichier build/handler.js généré par SvelteKit build en mode SSR.
Le fichier src/server.js est copié vers le dossier /build/ lors de l'exécution de pnpm run build.
J'ai testé le bon fonctionnement du POC dans un container Docker.
J'ai intégré au projet un deployment-playground : https://github.com/stephane-klein/poc-sveltekit-custom-server/tree/main/deployment-playground.
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Update du 2025-05-29 à 00:07 - Je viens de publier ceci :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/?
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Nom et arborescence de Monorepo
Je suis un adepe du paradigme Monorepo, de la documentation colocalisée et des issues colocalisées.
Je conseille de nommer le repository avec le nom de l'organisation.
Par exemple, si mon organisation se nomme « Dummy Tech » et si elle utilise GitLab, alors je conseille d'utiliser le slug dummy-tech, ce qui donne gitlab.com/dummy-tech/dummy-tech/ et « Dummy Tech Monorepo » comme titre de repository.
La neutralité de ce nom facilite les décisions concernant ce qui peut ou non être inclus dans le repository, sans être limité par un nom trop restrictif. Il est flexible face à l'évolution du projet. Il permet d'éviter bien des débats à propos du nommage.
En 2018, sur GitHub, j'ai découvert un exemple de monorepo d'une organisation. Cet exemple m'a servi de base et je l'ai fait évoluer quand je travaillais chez Spacefill.
Voici un exemple d'arborescence de monorepo que j'aime utiliser :
dummy-tech
├── deployments
│ ├── prod
│ └── sandbox
├── ci
├── docs
├── playgrounds
│ ├── playground_a
│ └── playground_b
├── services
│ ├── service_a
│ ├── service_b
│ └── service_c
└── tools
├── tool_a
├── tool_b
└── tool_c
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.